이 챕터에서는 비정규화를 살펴보자(정규화 링크는 여기)
사실 역정규화와 비정규화가 같은 의미로 쓰이는 것 같지만 엄연히 말하면 다르다.
비정규화(Unnormalized form)는 정규화된 테이블(릴레이션)을
읽기성능 향상을 위해 테이블을 다시 합치는 방법을 말하고
역정규화(Denormalization)는 정규화된 테이블을
비정규화 상태로 만들기 위한 방법 중 하나이다(비정규화가 더 포괄적임).
(※역정규화, Entity합체, Entity분해 등 여러 방법이 있지만 역정규화가 일반적이다)
하지만 여러군데 자료들을 찾아보니 비정규화하고 역정규화를
같은 의미(여러 비정규화 방법 중 역정규화 의미 쪽으로)로 사용하는 곳이 많았다.
(※혹시나 해서 용어 구분을 했지만 너무 신경 쓰지 말자. 어차피 역정규화 내용이 중요하다!)
비정규화 상태로 만드는 역정규화 프로세스는
데이터베이스의 완벽한 구조설계를 포기하고
데이터의 무결성을 떨어트리는 대신 관계형 데이터베이스의
읽기(Read)성능 향상을 위한 설계 방법이다.
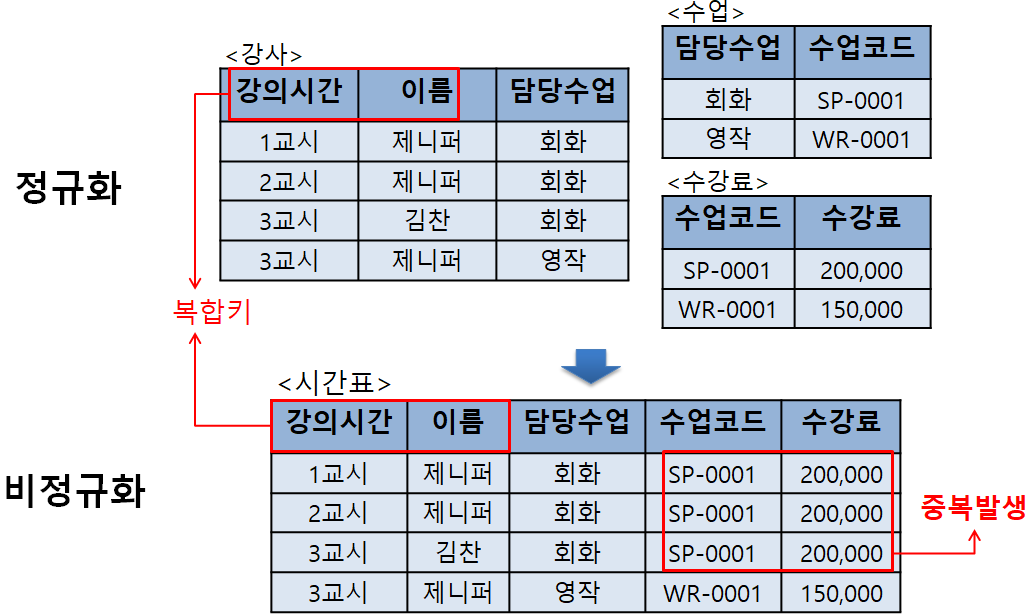
위 예시를 보자.
만약 내가 [3교시 선생님의 강의와 수강료]를 알고 싶다면 정규화된 테이블에서는
<강사>테이블에서 {강의시간, 이름, 담당수업}을 확인하고,
<수업>테이블에서 {수업코드}를 확인하고,
<수강료>테이블에서 {수강료}를 확인해야 한다.
우리 눈으로 볼 땐 테이블을 옮겨 다니며 하나씩 찾아가지만
컴퓨터는 저 3가지 테이블을 같은 키로 JOIN한 뒤 데이터 값을 찾는다.
만약 테이블 개수가 엄청 많거나 테이블 안에 데이터가 엄청 많으면
JOIN시간이 훨씬 늘어나 데이터 읽기 효율성이 떨어진다.
그래서 그림의 <시간표>테이블처럼 역정규화 시키면
JOIN을 할 필요가 없어 데이터 읽기(조회)시간이 단축된다.
하지만 비정규화를 할 때 고려해야 할 점이 많다.
1. 무결성(데이터의 정확성)이 떨어지는 것에 주의하자.
데이터 중복이 발생해 나중에 데이터를 수정할 때 일부만 수정되어
결국 저장된 데이터가 정확하지 않을 수도 있다. 항상 문제가 생기는 건 아니지만
데이터베이스에서 무결성은 가장 중요한 요소라서 민감한 부분이다.
2. 읽기(조회)속도는 빨라지지만 쓰기(삽입, 수정, 삭제)속도는 느려진다.
이 문제도 중복된 데이터 사본때문이다.
그러니 쓰기 작업보다 읽기 작업의 성능이 중요할 때 고려하자.
3. 저장공간의 효율이 떨어지는 것에 주의하자.
중복된 데이터의 공간 차지로 인해 데이터의 용량이 늘어난다.
4. 유지보수가 어렵다.
테이블 자체가 크고 복잡하여 쉽게 수정할 수 없고 이로 인해 확장성이 떨어진다.
이렇게 문제가 생기는데도 비정규화를 하는 이유는
오로지 성능 문제가 있는(읽기작업이 많이 필요한) 테이블 때문이다.
따라서 정규화, 비정규화를 사용하려면
데이터와 데이터베이스에 대한 이해도가 높아야 한다!
'공부-Data Engineer > 데이터베이스' 카테고리의 다른 글
| [쉽게 설명한] 데이터 웨어하우스 (0) | 2020.06.15 |
|---|---|
| [쉽게 설명한] 데이터베이스 정규화 (5) | 2020.06.11 |
| [쉽게 설명한] OLTP, OLAP (0) | 2020.06.09 |
| [쉽게 설명한] NoSQL (0) | 2020.06.08 |
| [쉽게 설명한] 관계형 데이터베이스 (0) | 2020.06.04 |



